Steven Morse personal website and research notes
Scraping ESPN Fantasy Football (in Python) - Part 3
Written on August 3rd , 2018 by Steven MorseEDIT: ESPN changed their Fantasy API to v3 in early 2019, so lots of v2 code from this post no longer works. Don’t worry we’re on it:
- Here’s an intro to using the new version.
- Here’s how to grab historical projections using the new version.
Check it out.
This is the third (and probably last) of 3 posts (here’s the first one and second one) on pulling info from ESPN Fantasy. This post focuses on how to pass personal session cookies in order to access info otherwise hidden behind a login. Caveat: to my knowledge there is nothing prohibited about passing one’s own personal cookies over a GET request, but you should review ESPN’s API Terms of Use yourself and obviously not provide your cookies to a third-party.
The Right Cookie
A lot of the ESPN Fantasy tools are behind a login-wall. Since accounts are free, this is not a huge deal, but becomes slightly annoying for GET requests because now we somehow need to “login” through the request. One way to do this is to send session cookies along with the request. Again this can take us into a gray area, but to my knowledge there is nothing prohibited about using your own cookies for personal use within your own league.
Specifically, our GET request from the previous post is modified to look like, for example:
r = requests.get('http://games.espn.com/ffl/api/v2/scoreboard',
params={'leagueId': 123456, 'seasonId': 2017, 'matchupPeriodId': 1},
cookies={'swid': '{SWID-COOKIE-HERE}',
'espn_s2': 'LONG_ESPN_S2_COOKIE_HERE'})
This should return the info you want even for a private league. I saw that the SWID and the ESPN_S2 cookies were the magic tickets based on the similar coding endeavors here and here and here.
You can find these cookies in Safari by opening the Storage tab of Developer tools (you can turn on developer tools in preferences), and looking under espn.com in the Cookies folder. In Chrome, you can go to Preferences -> Advanced -> Content Settings -> Cookies -> See all cookies and site data, and looking for ESPN.
Case Study: Free Agent stats
Besides accessing the API endpoints for private leagues, passing session cookies allows us to “scrape” data from other league sites. For example, the player stats page. This is valuable because it gives us historical data on all players, not just the few that happened to be on rosters in a given week (which we can get through the boxscore endpoint, see previous post).
The page we’re interested in is http://games.espn.com/ffl/leaders?leagueId=123&seasonId=2017, the weekly leaderboard. Adding BeautifulSoup to the list of libraries from the previous posts, let’s just pull QBs from week 1:
from bs4 import BeautifulSoup
r = requests.get('http://games.espn.com/ffl/leaders',
params={'leagueId': 12356, 'seasonId': 2017,
'scoringPeriodId': 1,
'slotCategoryId': 0},
cookies={'SWID': swid, 'espn_s2': espn})
soup = BeautifulSoup(r.content, 'html.parser')
table = soup.find('table', class_='playerTableTable')
tdf = pd.read_html(str(table), flavor='bs4')[0] # returns a list of df's, grab first
Line by line, this imports the BeautifulSoup library from bs4 which is a high-level HTML/CSS handler (so we can avoid some nasty text scraping of the raw HTML in r.content). Then we do the request to the leaderboard page, being sure to pass cookies. We create soup, a BeautifulSoup object that allows us to soup.find the HTML table with class playerTableTable which I happen to know is the class of the table we want (discovered by skimming the page source).
Lastly, we give a raw-string version of this table to pandas, which works some magic and turns it into a DataFrame.
We get:
0 1 2 3 4 5 6 7 8 9 ... 17 18 19 20 21 22 23 24 25 26
0 OFFENSIVE PLAYERS NaN STATUS NaN WK 1 NaN PASSING NaN RUSHING NaN ... NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN
1 PLAYER, TEAM POS NaN TYPE ACTION NaN OPP STATUS ET NaN C/A YDS ... REC YDS TD TAR NaN 2PC FUML TD NaN PTS
2 Alex Smith, Wsh QB NaN FA NaN NaN Phi L 17-30 NaN 28/35 368 ... 0 0 0 0 NaN 0 0 0 NaN 54
3 Matthew Stafford, Det QB NaN BREW NaN NaN Ari W 35-23 NaN 29/41 292 ... 0 0 0 0 NaN 0 0 0 NaN 39
4 Sam Bradford, Ari QB NaN FA NaN NaN @Det L 23-35 NaN 27/32 346 ... 0 0 0 0 NaN 0 0 0 NaN 37
All we want for now is player name (col 0), team/FA status (2), and total points for the week (26). A bit of wrangling:
tdf = tdf.iloc[2:, [0,2,26]].reset_index(drop=True)
tdf.columns = ['Player', 'Owner', 'Pts']
tdf['Pts'] = tdf['Pts'].fillna(0).astype('int')
tdf['Player'] = tdf['Player'].str.split(',').str[0] # keep just player name
tdf['Week'] = 1
Wrap this in a loop and get every week for the season:
leagueId, seasonId = 123456, 2017
slot = 0
df = pd.DataFrame(columns=['Player', 'Owner', 'Pts', 'Week'])
print('Week ', end='')
for week in range(1, 17):
print('%d .. ' % week, end='')
# do first two "pages" of results
for si in [0, 50]:
r = requests.get('http://games.espn.com/ffl/leaders',
params={'leagueId': leagueId, 'seasonId': seasonId,
'scoringPeriodId': week,
'slotCategoryId': slot,
'startIndex': si},
cookies={'SWID': swid, 'espn_s2': espn})
soup = BeautifulSoup(r.content, 'html.parser')
table = soup.find('table', class_='playerTableTable')
tdf = pd.read_html(str(table), flavor='bs4')[0] # returns a list of df's, grab first
tdf = tdf.iloc[2:, [0,2,26]].reset_index(drop=True)
tdf.columns = ['Player', 'Owner', 'Pts']
tdf['Pts'] = tdf['Pts'].fillna(0).astype('int')
tdf['Player'] = tdf['Player'].str.split(',').str[0] # keep just player name
tdf['Week'] = week
df = df.append(tdf)
print('Complete.')
This gives:
Player Owner Pts Week
0 Alex Smith FA 54.0 1.0
1 Matthew Stafford BBB 39.0 1.0
2 Sam Bradford FA 37.0 1.0
3 Carson Wentz JJ 32.0 1.0
4 Matt Ryan JJ 30.0 1.0
You could easily add a loop to grab multiple seasons and really try to do some forecasting based on long-term trends …. sounds like a real project. For now, let’s look at the distribution of total points, and whether the player was actually a consistent starter or one of those waiver wire gems that got picked up late (or never at all?). First we might make some summary stats
cstats = (df.groupby('Player')
.agg({'Pts': 'mean'})
.reset_index()
.rename(columns={'Pts': 'Avg pts'}))
cstats['FA'] = (df.groupby('Player')['Owner']
.apply(lambda x: x[x=='FA'].count())
.as_matrix())
cstats.head()
Player Avg pts FA
0 AJ McCarron 0.133333 15
1 Aaron Murray 0.000000 15
2 Aaron Rodgers 11.933333 0
3 Alex Smith 26.000000 3
4 Alex Tanney 0.000000 15
This gives the overall average points and the number of weeks the player was on the waiver wire (out of 15 possible, since fantasy usually stops a week early and teams have a bye).
We can use this to do a boxplot viz of point distribution, colored by whether the player was on a roster for at least half the season or not. And thus was born another matplotlib/seaborn mashup, with a loop and a dummy scatter plot because I couldn’t figure out how to make this happen using FacetGrid!
cz = cstats[cstats['Avg pts'] >= 10]
z = df[df['Player'].isin(cz['Player'])]
z = pd.merge(z, cz, on='Player', how='outer')
z['FA'] = pd.cut(z['FA'], bins=2, labels=['Season starter', 'Waiver wire'])
fig, ax = plt.subplots(1,1, figsize=(12,10))
for i, c, lab in [(0,'royalblue','Season starter'), (1, 'aliceblue', 'Waiver wire')]:
sns.boxplot(data=z[z['FA']==lab],
x='Pts', y='Player',
color=c,
order=cz.sort_values('Avg pts')['Player'],
orient='h',
ax=ax)
ax.scatter([], [], c=c, edgecolors='k', label=lab) # dummy for legend
ax.legend()
ax.set(xlabel='Points', ylabel='',
title='Player Scores (Season starters vs. waiver wire)')
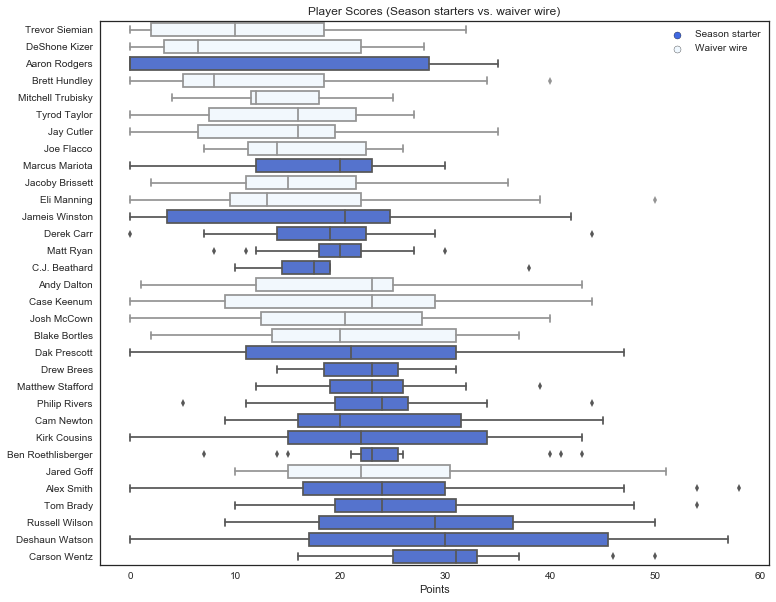
Look at how many good-to-great QBs were on the waiver wire (in this league) for over half the season!
That’s all for now. Send questions/comments to @thestevemo or feel free to email me.
Written on August 3rd , 2018 by Steven Morse