Steven Morse personal website and research notes
Using the ESPN Fantasy Football API (in Python)
Written on June 27th, 2018 by Steven MorseEDIT: ESPN changed their Fantasy API to v3 in early 2019, so lots of v2 code from this post no longer works. Don’t worry we’re on it:
- Here’s an intro to using the new version.
- Here’s how to grab historical projections using the new version.
Check it out.
Fantasy football season approacheth. Your heart longs to analyze the scoring distribution in your league by week, by team, by player — to finally quantitatively question the predictive power of projected points — to confirm your hypothesis that you got an unfair slate of opponents in the pre-playoff weeks … and yet you know not how. Copy-paste data from a webpage? Do some expert-level web scraping?
You’re in luck. ESPN has an accessible, though undocumented, API for their Fantasy football database. This means you can query a question like “what was the score of the week 1 game between ABC and XYZ” directly with a GET request and some JSON fiddling, no web “scraping” required.
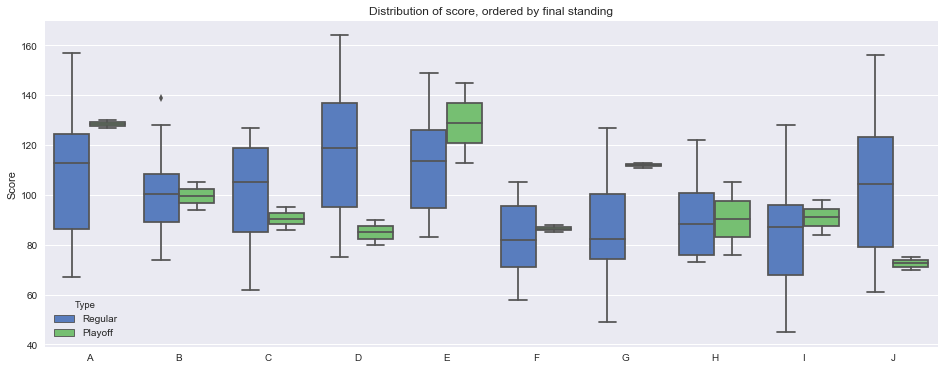
Since the API is mysteriously undocumented, in this blog I’ll write down everything I’ve learned about the API, how to access different parts of it, and how to do that in Python and R. In a follow-on post, I’ll show how to get boxscores, and then how to deal with private leagues. Here’s a boxplot we’ll produce:
Before we get started, let the reader note there’s already a Python package out there that do a lot of what I describe below in a clean way: espnff. So you can skip the hassle and just use this excellent work. My feeling is: I’d rather bake my own janky cake with all the toppings I want than buy the tasty more attractive cake from the store.
You should also check out my friend Dusty Turner’s excellent post about ESPN Fantasy scraping in R, and this Reddit discussion about the ESPN Fantasy API.
CAVEAT: your league needs to be “public”, or you need to figure out how to send session cookies or login remotely, see end of this post.
Looking at scores (in Python)
Let’s start with Python. Using the requests package for our GET request, let’s tap into the ESPN Fantasy API through the scoreboard endpoint:
import requests
scores = {}
for week in range(1, 17):
r = requests.get('http://games.espn.com/ffl/api/v2/scoreboard',
params={'leagueId': 123456, 'seasonId': 2017, 'matchupPeriodId': week})
scores[week] = r.json()
Let’s walk through this line by line. Import the requests package. Initialize a dict called scores to hold score information. Loop over weeks 1-16. Do a GET request to the API at http://games.espn.com/ffl/api/v2/ with the endpoint scoreboard, and with parameters for the league ID, season, and matchup period. To find your league ID, check the URL when you’re on your league’s page. Note: if we don’t specify the matchup period, it will default to the last week. Finally, store that week’s score information in scores as a dict in JSON format.
The GET request above, with parameters, is essentially equivalent to if you entered the following URL into a browser:
http://games.espn.com/ffl/api/v2/scoreboard?leagueId=123456&seasonId=2017&matchupPeriodId=1
and then saved the resulting text (which notice is in a JSON format).
It is worth poking around this nested collection of information. Here’s an abbreviated sample of scores[1]:
{'metadata': { ... },
'scoreboard': {'dateFirstProGameOfScoringPeriod': '2017-09-08T00:30:00.000Z',
'matchupPeriodId': 1,
'matchups': [{'bye': False,
'teams': [{'home': True,
'playerIDs': [ ... ],
'score': 81,
'team': {'division': {'divisionId': 0,
'divisionName': 'Division 1',
'size': 5},
'record': { ... },
'teamAbbrev': 'ABCD',
'teamId': 5,
'teamLocation': 'Team ',
'teamNickname': 'Smith',
'waiverRank': 2},
'teamId': 5}, ... ],
'winner': 'away'},
... ]}
There is a ton of information stored here already, and we’re only using one endpoint! We’ll focus on scores for now, but at the end of this post, I’ll mention some other potential here such as those playerIDs (i.e. the players on each team, by week!).
To extract the first matchup of week 1, we would do scores[1]['scoreboard']['matchups'][0]. To extract the home score for this matchup, we would index deeper and call scores[1]['scoreboard']['matchups'][0]['teams'][0]['score']. To make a clean table of all the team IDs, names, and scores for all weeks, we can do
df = []
for key in scores:
temp = scores[key]['scoreboard']['matchups']
for match in temp:
df.append([key,
match['teams'][0]['team']['teamAbbrev'],
match['teams'][1]['team']['teamAbbrev'],
match['teams'][0]['score'],
match['teams'][1]['score']])
I’d like to start visualizing this information with matplotlib, and to make our lives easier let’s bring numpy, pandas and seaborn to the mix.
%matplotlib inline
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import seaborn as sns
(The matplotlib inline is some magic to get inline plots in a Jupyter notebook, omit if you are working in another setting.)
Now we can save our table as a pandas DataFrame, let’s take a look at it:
df = pd.DataFrame(df, columns=['Week', 'HomeAbbrev', 'AwayAbbrev', 'HomeScore', 'AwayScore'])
df.head()
Let’s get rid of the (let’s admit, completely arbitrary) home-away distinction and just get a dataframe of all scores by team. Let’s also add a categorical variable Type for whether the game was regular season or playoff.
df = (df[['Week', 'HomeAbbrev', 'HomeScore']]
.rename(columns={'HomeAbbrev': 'Abbrev', 'HomeScore': 'Score'})
.append(df[['Week', 'AwayAbbrev', 'AwayScore']]
.rename(columns={'AwayAbbrev': 'Abbrev', 'AwayScore': 'Score'}))
)
df['Type'] = pd.Series(['Regular' if w<=14 else 'Playoff' for w in df['Week']])
To protect the innocent, I renamed all the teams “A”, “B”, “C”, … Here’s my df.head()
Week Abbrev Score Type
0 1 I 81 Regular
1 1 G 126 Regular
2 1 F 69 Regular
3 1 J 61 Regular
4 1 A 99 Regular
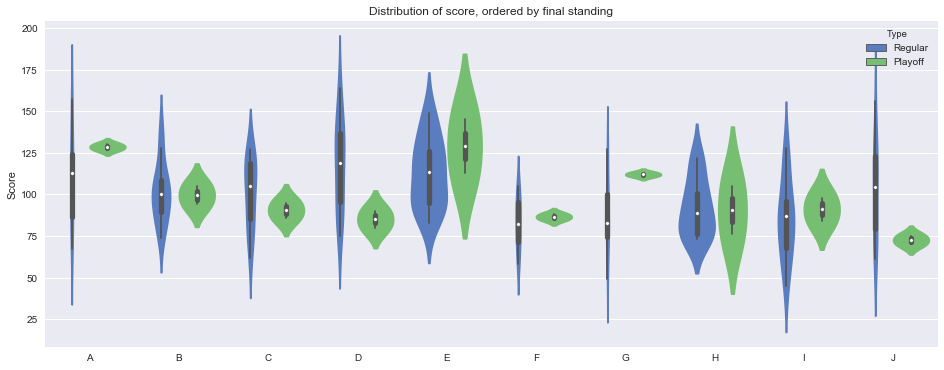
Now we do some plots. Let’s look at a violin plot of scores, by player, regular/playoff game, and ordered by final standing (which I conveniently already ensured was in alphabetical order, but of course you could specify any order you want, like ['BOB', 'ANN', ...]).
fig, ax = plt.subplots(1,1, figsize=(16,6))
sns.violinplot(x='Abbrev', y='Score', hue='Type',
data=df,
palette='muted',
order=list('ABCDEFGHIJ'))
ax.set_xlabel('')
ax.set_title('Distribution of score, ordered by final standing')
plt.show()
If you change violinplot to boxplot in the above code, you’ll get the image at the start of this blog.
A few stories here: high scorers are unsurprisingly in higher standing than low scorers. Consistency doesn’t seem to matter much, as there are high variance teams at top and bottom. But playoff performance absolutely does matter for the playoff teams (in this case, top 4) — in fact, Player D entered the playoffs as top seed and finished 4th. Player E had the best playoff performance but had too many mediocre games in the regular season. All tales as old as time.
Doing it in R
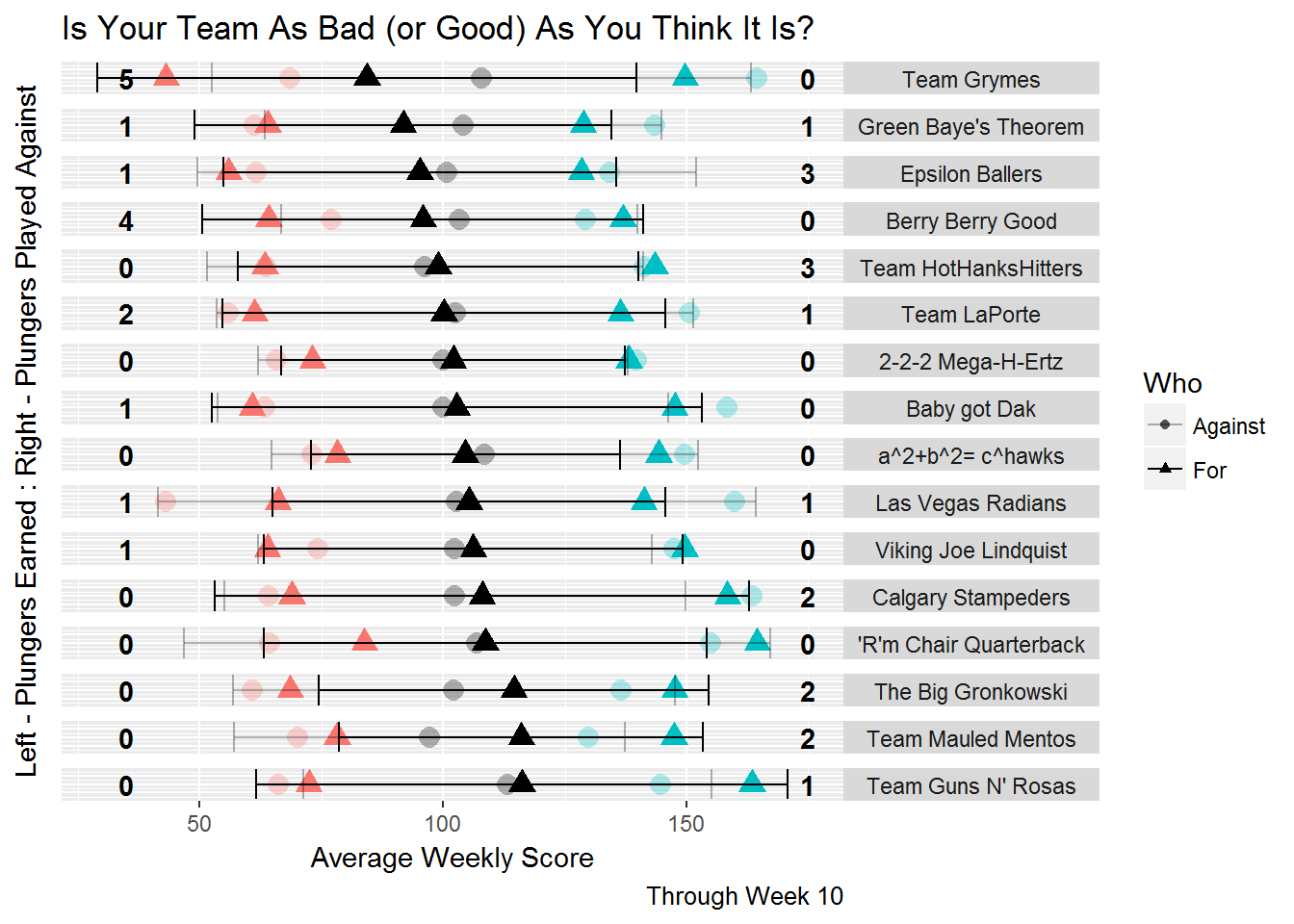
I thought about redoing the above process in R, but realized @DTDusty already did it better: check out his blog over here. Here’s a teaser pic, whose filename let the reader note is dusty_fantasy.png …
Other endpoints, private leagues…
Another rabbit hole to explore is the various other “endpoints” to the API besides scoreboard. Here’s several that I know about:
- leagueSettings
- playerInfo
- scoreboard
- player/news
- recentActivity
- leagueSchedules
- teams
- rosterInfo
- schedule
- polls
- messageboard
- status
- teams/pendingMoveBatches
- tweets
- stories
- livescoring (doesn’t seem to be working right)
- boxscore
Each of these can be appended to the ESPN API URL and be explored.
I’m most interested in boxscore which contains the weekly points by player. However, it only returns the full information if you are logged into an account, which I’ve been unable to do through a GET request. Try it: log in to your ESPN account, and then enter the API URL
http://games.espn.com/ffl/api/v2/boxscore?leagueId=123456&seasonId=2017&matchupPeriodId=1
with your league ID. All the desired info will pop up. Now try through a GET request and you’ll get basically an empty dict. This indicates there is some cookie/swid/other stuff being passed behind the scenes for this endpoint. It is possible to send espn_s2 cookies, swid, and other info in the GET request, but I haven’t gotten these to work. If you’ve cracked the code on this, please let me know.
EDIT: I think it be as simple as adding a teamId parameter, but more to follow in a later post …
EDIT2: It was: check out the follow-on posts on how to get boxscores, and then how to deal with private leagues.
Hope this has been enjoyable, good luck this season!
Written on June 27th, 2018 by Steven Morse